原文链接:http://deniable.org/reversing/binary-instrumentation
原文日期:Jul 25, 2018
原作者: rui
因原文较长,翻译分为2部分。此文为第1部分,覆盖原文的1-5章。
- 介绍
Instrumentation(修改)
动态程序分析
性能
- Pin
Pin配置(Windows)
Pin与Visual Studio集成
- DynamoRIO
DynamoRIO配置(Windows)
DynamoRIO与Visual Studio集成
- Frida
Frida配置(Windows)
- 通用DBI用法
用户定义的修改
- 示例工具
目标/客户程序(ExercisePin.exe)
PinTool基础版(MallocTracer)
DynamoRIO基础版(MallocWrap)
Frida脚本基础版(MallocLogger)
- 调试
- 使用PinTool追踪Windows堆内存分配API
- 总结
- 参考文献
动态二进制修改(DBI)是一种在二进制程序运行时通过注入修改代码来分析程序行为的方法 – Uninformed 2007
一.介绍
这篇文章的目的是记录我研究动态二进制修改的过程以及一些心得。我会介绍一些最知名且常用的DBI框架,即:Pin,DynamoRIO和Frida。其中我将主要介绍Pin。市面上还有其他DBI框架我这里不会提及,比如Valgrind,Triton(使用Pin),QDBI,BAP,Dyninst以及许多其他框架。不过你没准儿会有点儿兴趣想研究研究。这些框架有的成熟一些,有的则不太成熟;有的功能多,有的功能少。你必须自己研究一番,才能知道哪些能满足你的需求。 对了,即使 Valgrind 是最广为人知的且使用最广泛的DBI框架之一,因为它只适用于Linux,所以,此文也不会提它。
我做漏洞挖掘也有些年头了,一直专注于Windows,事实上,如果你想要拿我在文中贴的代码在Linux上编译应该也是非常简单的,不过反过来就不行了。原因是,在Windows编译Pin或DynamoRIO可能有点令人沮丧,特别是不非得这么做的时候。
我不是DBI领域的专家,但从今年年初开始,我一直在做一些跟Fuzzing有关的实验,而且我已经阅读了很多关于DBI的内容。因此,我将尝试记录我学到的一些内容以供将来参考。可能你也会发现一些有用的东西。请注意,我的目标是编写参考而不是教程。
有趣的是,在尝试做一些浏览器堆喷射(Heap Spraying)时,我实际上考虑过使用Pin或DynamoRIO做“一些事情”。最基本的,我想监视我的代码分配的内存。虽然在调试器中我也可以做到这一点,但我想“为什么不使用DBI框架?也许我可以学到一些东西”。毕竟,调试器太慢了。直到今天,我仍然不确定我更愿意使用 Windbg 还是 Pin。
1.1 Instrumentation(修改)
根据维基百科,修改(instrumentation)指的是监控或衡量产品性能水平,诊断错误和获取跟踪信息的能力。程序员通过编写代码,监视系统中的特定组件,来实现修改(…)。对于应用程序包含的修改代码,可以使用管理工具对其进行管理。修改过程必须检查应用程序的性能。修改的实现方法有两种类型:源代码修改和二进制修改。
首先,源代码修改,如果你没有软件应用程序的源代码,自然是不可能的。而二进制修改,只要软件可以执行,任何软件都可以搞。事实证明, 在Windows操作系统上运行的大多数程序都是闭源的。这意味着,在这篇文章中,我只会“谈”二进制修改。因为完整的单词Dynamic Binary Instrumentation太占地儿,通常人们会使用首字母缩略词DBI,正如我上面所做的那样。
总之一句话,DBI是一种将修改代码注入正在运行的进程的技术。注入的修改代码对于被注入进程来说,是完全透明的。
使用DBI框架,我们可以一步一步的分析目标二进制文件。但请注意,可分析对象仅包括实际执行过的代码。
1.2 动态程序分析
通常程序分析方式有2种:静态和动态。静态分析不需要运行程序,动态则需要运行程序。
再次引用维基百科,动态程序分析是通过在真实或虚拟处理器上执行程序,来对计算机软件进行分析。要使动态分析足够有效,目标程序必须使用足够多的测试输入执行多次,以产生某些你感兴趣的行为。使用诸如代码覆盖之类的软件测试手段,有助于确保观察到程序的足够多的可能的行为。
DBI工具,如前面提到的那些,在正在运行的程序和底层操作系统之间引入了一个层。由此提供了一个在程序执行时检查和修改用户级程序指令的独特机会。
这些DBI框架内部非常复杂。但是,所有复杂性都被API掩盖了。任何用户都可以使用API快速构建大量工具来辅助软件分析。我会在此文中分享我在使用这些DBI框架时编写的代码,阅读过这些代码,你就知道我所言非虚。
我们要观察和修改程序运行时行为的原因有很多。软件和/或硬件开发人员,系统工程师,漏洞挖掘,恶意软件分析师,软件使用用户等,每个人都有自己的理由。DBI框架能够让我们接触到程序执行的每一个用户级指令。除了可能很小的运行时和内存开销之外,程序跟直接执行没有什么不同。
你可以说静态分析的主要优点是它可以确保100%的代码覆盖率。动态分析时,要确保高代码覆盖率,就需要多次运行程序,并使用不同的输入,程序才会执行不同的代码路径。但是,在某些情况下,软件非常庞大,执行静态分析的成本太高。所以说,术业有专攻。即便静态分析那么的无聊,动态分析那么的有趣。
我前面说过,DBI框架直接在二进制文件/可执行文件中运行。我们不需要程序的源代码。我们不需要(重新)编译或(重新)链接程序。显然,这在我们分析专有软件时,是一个绝对优势。
DBI与 “guest”程序同步运行,并且在运行中动态执行所有必要的和请求的修改。这种动态修改的方法还可以处理动态生成代码的程序(当然这对设计是个巨大的挑战),即自修改代码。如果你稍微“谷歌”一下,就会发现很多使用DBI框架分析具有自修改代码的恶意软件的案例。例如,去年的blackhat Europe的演示文稿。或者,这个使用Pin脱壳Skpye的帖子。
用DBI框架解决计算机体系结构问题的案例每天都会有,在软件工程,程序分析和计算机安全方面的应用更是广泛。软件工程师希望深入了解他们开发的软件,系统地分析其性能和运行时行为。DBI框架的一个常见用途是模拟新的CPU指令。由于DBI在系统执行每条指令之前都可以对其访问/修改,因此硬件工程师可以使用DBI系统来测试当前不受硬件支持的新指令。DBI会模拟特定指令的行为,而不是执行这条指令。可以使用相同的方法来替换错误指令,并正确模拟所需行为。总之,从计算机安全的角度看,我们可以将DBI系统用于系统控制流分析,污点分析(taint analysis),fuzzing,代码覆盖,测试案例生成,逆向,调试,漏洞检测,甚至做一些疯狂的事情,比如给漏洞打补丁,以及自动化的漏洞开发。
DBI系统主要有两种使用方式。第一个,也是最常见的(至少计算机安全领域),是在DBI系统的控制下将程序从头执行到尾。当我们想要完整的模拟/仿真系统时,会使用这种方式,因为我们需要对程序的完全控制以实现完整的代码覆盖。第二种,我们可能只想附加到正在运行的程序(跟调试器附加/分离被调试器进程的方式完全相同)。如果我们想知道某个程序在某个时刻正在做什么,此种方式最是有用。
此外,大多数DBI框架都有三种执行模式。解释(Interpretation)模式,探测(probe)模式和即时(JIT)模式。DBI系统支持多种执行模式,但JIT模式无疑是最常见的、也是最常用的模式。在JIT模式下,原始二进制文件/可执行文件实际上从未被修改或执行。二进制文件被视为数据,然后在新的内存区域中生成二进制文件的修改副本(但仅适用于二进制文件的已执行部分,而不是整个二进制文件),实际执行的也是修改后的副本。在解释模式中,二进制也被视为数据,每个指令用作具有相应功能(由用户实现)的指令速查表。在探测模式下,二进制文件的指令实际上被新指令覆盖了。当然这会导致一点儿运行时间开销,但在某些体系结构(如x86)中开销非常有限。
无论哪种执行模式,一旦我们通过DBI框架控制程序的执行,我们就能够对其进行修改。我们可以在代码块之前和之后插入我们的修改代码,甚至完全替代码块都可以。
下图为DBI框架的工作原理。
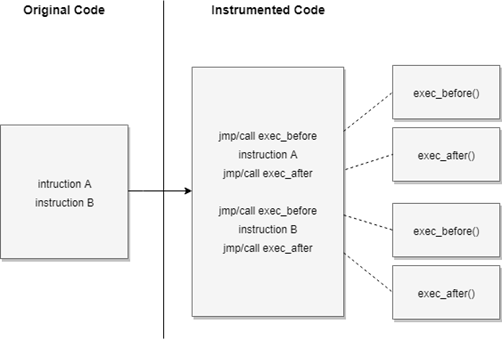
此外,DBI系统有不同类型的控制粒度:
- 指令级别
- 基本块级别
- 函数级别
选择不同的粒度, 对程序执行自然有不同程度的控制权。显然,这会对性能产生影响。另外,请注意,在大多数情况下,对整个程序进行修改是不切实际的。
1.3 性能
你可能会想,动态修改正在运行的程序会对性能产生什么影响。好吧,对于回答这个问题我的经验非常有限。然而,在阅读了多篇论文,文章和文稿之后,通常观察到的开销实际上取决于随机数量的因素。无论如何,开销的一大部分,都来源于用户所做的修改。根据观察, 30%是观察到的平均数。真的不记得这个数字是我在哪里读到的,但我肯定在某处读到过。不过你肯定可以在参考章节找到它。使用DBI系统时,必须做出的第一个决定之一就是:根据你的需求决定代码覆盖率,以及你可以接受的合理的性能开销。
二.Pin
Pin是由英特尔公司开发的DBI框架。我们可以使用Pin来为Windows, Linux和OSX系统构建分析工具,也就是Pintools。我们可以使用这些工具来监视,修改和记录程序行时的行为。
Pin是专有软件。但是,我们可以免费下载和使用(非商业用途)。除了文档和二进制文件之外,Pin还包括大量示例程序Pintools及源码。这些都是非常宝贵的例子,在开发之前我们必须必须阅读这些Pintools的源码。
在我看来,Pin是最容易使用的DBI框架。至少研究它的API比研究DynamoRIO的API容易。虽然我没有花太多时间去学习其他工具的API,但我还是稍微看了看。例如Valgrind,Triton,Dyninst和Frida。老实说,选择哪个DBI框架取决于你打算做什么。
如果你想创建一个商业工具并部署它的二进制版本,Pin不是一个好的选择。如果不是这样,Pin可能是一个非常好的选择。根据我做的测试,Pin是稳定且可靠的。我在某些DBI框架下运行某些程序时遇到了不少问题。主要是大型程序,如Office套件,游戏和AV引擎。甚至是小应用程序,有些DBI框架也惨遭失败。
2.1 Pin 配置(Windows)
在Linux中设置Pin非常简单。但是,在Windows系统上,就有点棘手了。如果你想尝试我在本文中提供的示例,请参见下文如何快速设置和使用的说明。
从这里获取Pin的最新版本,并将其解压到C:\目录,或其他任何你喜欢的地方。为简单起见,我经常使用C:\pin。如果你计划复制本文贴的代码片段,我建议你也这样做。
Pin压缩包文件包括大量Pintools样例,在 source/tools 目录下。稍后你会看到,Pin的API很容易阅读和理解。读完这篇文章,你应该能够无障碍阅读大多数示例的源代码(好吧,某种程度上)。
我喜欢Visual Studio,我会用它来编写这篇文章中提到的“每个”工具。有一个Pintool样例,你只需要调整几个设置,然后几乎就可以直接使用Visual Studio编译了。但是,我不想每次创建新的Pintool项目时,都要手动复制和重命名这些文件。因此,我创建了个已经调整好了的示例项目,可从这里下载,然后跟这里的Python脚本一起放在C:\pin\source\tools目录下。这个脚本受到了Peter脚本的启发。但是,由于新版本的Visual Studio保存设置的方式已更改,我不得不重新编写/创建一个全新的脚本。
所以,每次你想要使用Visual Studio建立一个新Pintool项目时,只需:
cd\
cd pin
python create_pintool_project.py -p <name_of_your_project>
然后,你可以双击该项目的解决方案文件,使用Visual Studio编译之,不会有任何问题。我用的Visual Studio Professional 2015,但使用Visual Studio 2017也可以。我用Visual Studio 2017 Enterprise编译了几个,没出现任何问题。
2.2 Pin 与 Visual Studio 集成
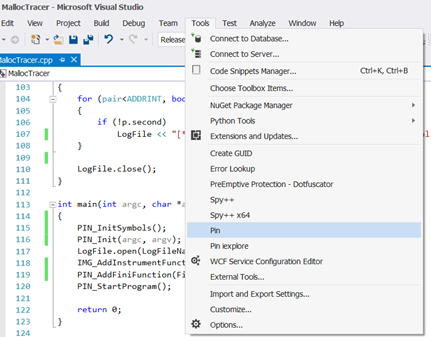
我们可以添加我们的Pintools作为Visual Studio的外部工具。然后运行、测试Pintool就不用一直使用命令行了。配置非常简单。从Tools菜单中选择External tools,出现一个对话框。单击Add按钮并根据下图填写文本输入框。

在Title栏的文本框中,输入你喜欢的任何内容。在Command栏文本框中输入pin.exe的完整路径,如果安装在c:\pin,就是c:\pin\pin.exe。在Arguments栏,必须包含要传递给Pintool的所有参数,至少需要上图中指定的那些。参数-t指定Pintool路径,– 之后的参数是要修改的目标程序。
设置完成后,您只需从Tools菜单中运行Pin,如下图所示。
点击 ok,开始享受吧。
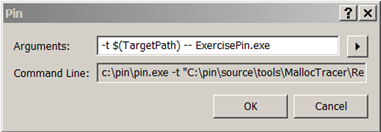
不论你的Pintool在向标准输出(stdout)中写什么, Visual Studio 的 Output 窗口都会显示。
三.DynamoRIO
另一个DBI框架DynamoRIO,最初是由惠普的Dynamo优化系统与麻省理工学院的运行时内省和优化(RIO)研究小组合作开发的。我们可以使用DynamoRIO为Windows和Linux系统构建程序分析工具,构建的工具称为clients。我们可以使用这些工具来监视,修改和记录程序运行时的行为。
DynamoRIO在2002年作为专有的二进制工具包首次发布,后来在2009年以BSD许可证开源。跟Pin一样,它也附带了多个client示例的源代码。这些示例对于我们入门和学习其API都非常宝贵。
DynamoRIO是一个运行时操纵代码的系统,可以在程序运行时对程序任何部分的代码进行置换。它作为应用程序和操作系统之间的中间平台。
我前面也说过,DynamoRIO的API并不是最友好和易于使用的。但是,如果你计划制作商业版本和/或部署二进制版本,那么DynamoRIO可能是最佳选择。它的一个优点是它是BSD许可的,这意味着软件免费。如果这对你很重要,那就赶紧试试吧。
另请注意,DynamoRIO的速度比Pin快是公认的(查看参考章节)。然而,同样公认的是Pin比DynamoRIO更稳定可靠,这一点我在运行大型软件程序时亲身体验过。
3.1 DynamoRIO 配置 (Windows)
在Windows系统安装DynamoRIO,只需从此处下载最新版本(撰写本文时版本为DynamoRIO-Windows-7.0.0-RC1.zip),然后解压到C:\dynamorio目录,跟上面配置Pin一样。
在Windows上编译自己的DynamoRIO项目,会有点棘手。您可以尝试按照这里或这里的说明进行操作,或者为了避免麻烦,只需…使用我的DynamoRIO Visual Studio模板项目。
我创建了一个已经修改过所有必需修改的includes和libs的示例项目(假设你的DynamoRIO在我之前提到的目录中解压缩),可以在这里下载。然后,跟上面配置Pin时差不多,也可以在这里下载python脚本。由于项目的文件结构有点不同,不能使用之前编写的脚本来克隆项目,于是我不得不为DynamoRIO专门创建一个。
因此,每次要使用Visual Studio创建新的DynamoRIO client项目时,只需执行以下操作:
python create_dynamorio_project.py -p <name_of_your_project>
以上命令假定前面提到的Python脚本和模板项目都在同一个文件夹中。
然后,你可以双击该项目的解决方案文件,使用Visual Studio无痛编译DynamoRIO client。我用的Visual Studio Professional 2015,但也可以使用Visual Studio 2017。我用Visual Studio 2017 Enterprise编译了几个,没出任何问题。
3.2 DynamoRIO 与 Visual Studio 集成
我们也可以把DynamoRIO集成到Visual Studio的外部工具中,集成方式与Pin完全相同。由于设置过程完全相同,我这里只贴一张截图,你可以自己完成剩下的工作。
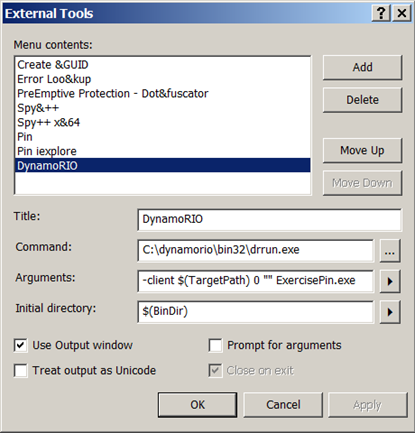
四.Frida
Frida是一个主要由Ole开发的DBI框架。它在“移动”社区中非常受欢迎,并有相当多的贡献者(现在由NowSecure赞助)。Frida支持OSX,Windows,Linux,和QNX,并且它的API支持多种语言,如Python,C#,Swift,Qt\QML和C。跟上面提到的DBI框架一样,我们可以结合使用Frida和脚本来监视、修改和记录程序运行时的行为。
Frida是免费的(免费啤酒的那种免费),非常容易安装(见下文)。也有许多在线用法示例,可以作为我们的入手点。Frida将谷歌的V8引擎注入到进程中。然后,Frida核心与Frida代理(进程端)通信并使用V8引擎运行JavaScript代码(创建动态钩子)。
Frida的API主要有两个部分:JavaScript API和绑定 API。我没有深入研究它们,只是使用了我认为最受欢迎的JavaScript API。然后发现它确实容易使用,非常灵活,我可以用它来快速编写一些探查工具。
尽管Pin和DynamoRIO是“主流的”DBI的框架,而且是最成熟的,但Frida还是有自己的优势。如上所述,它具有针对许多语言的绑定,并且开发工具的速度可以很快。与其他框架相比,它还有一些不足,例如,成熟度较低,文档较少,控制粒度较小,以及缺乏某些功能。
4.1 Frida 配置(Windows)
Frida的设置非常简单。只需下载https://bootstrap.pypa.io/get-pip.py然后运行就OK了:
python get-pip.py
要实际安装Frida只需执行:
cd\
cd Python27\Scripts
pip.exe install frida
就酱紫。是的,在上述步骤之前,你必须安装Python。然而,我可不认识任何没有安装Python的人,所以我假设你的Python环境已经装好了。
五.通用DBI用法
在写代码之前,我会在本节中记录使用我前面提到的DBI框架的一般方法。更确切地说是Pin和DynamoRIO。
如前所述,DBI系统最常用的模式是JIT(即时编译)模式。JIT编译器会在执行指令之前创建指令块的修改副本,并将这些副本缓存在内存中。这种执行模式是我看过的大多数DBI框架的默认模式,并且通常也被认为是最强大的执行模型。
同时,我还说过,主要有两种控制程序执行的方法。第一种是在DBI框架的控制下运行整个程序。第二种是附加到正在运行的程序,就像个调试器一样。
以下是在DBI系统控制下运行程序的标准方法。我们的目标/guest应用程序不是从命令行直接启动的。相反,应用程序路径作为参数传递给DBI系统。DBI系统初始化自身,然后在其控制下启动程序,并根据插件修改该程序。插件包含实际的用户定义代码,即我们的修改代码。对于Pin,这种插件叫Pintool;对于DynamoRIO,它叫client;对于Frida,我认为简单点儿叫脚本就行?
PIN JIT 模式:
pin.exe <pin args> -t <pintool>.dll <pintool args> — target_program.exe <target_program args>
PIN 探查(Probe)mode:
pin.exe -probe <pin args> -t <pintool>.dll <pintool args> — target_program.exe <target_program args>
DynamoRIO JIT 模式:
drrun.exe -client <dynamorio client>.dll 0 “” target_program.exe <target_program args>
DynamoRIO 探查(Probe)模式:
drrun.exe -mode probe -client <dynamorio client>.dll 0 “” target_program.exe <target_program args>
如上所见,我们启动Pin和DynamoRIO的方式并没有什么不同。在Linux系统中,几乎都是这个样子的(是的,删除.exe, 用.so替换.dll,就OK了)。
显然,除了上面显示的选项之外,还可以在命令行上传递许多其他选项。有关完整列表,请查看帮助/手册页。以上只是必须的选项。
Frida就不一样了,我们在后面会看到如何使用它。
如果要附加到正在运行的进程,可以用Pin来做。起码截至目前最新版本,DynamoRIO依然不支持附加到进程。但是,在Windows系统上由DynamoRIO控制进程的执行有两种方法。你可以在这里阅读更多相关信息。
使用Pin,你可以使用-pid参数连接进程,非常简单,如下所示:
pin.exe -pid <target pid> <other pin args> -t <pintool>.dll <pintool args>
5.1 用户定义的修改
不论哪个DBI框架,都提供了一套API,我们可以用来修改目标/guest程序。由API引入的功能通常与某种编程语言编写的代码(一般是C/C++, Frida甚至可以使用JavaScript和Swift)一起构造成一个插件(以我们在上面看到的共享库的形式),然后由DBI系统将其“注入”到运行的目标/guess程序中。然后插件将在目标/guest程序的相同地址空间中运行。
这意味着为了使用DBI系统,我们不仅需要知道如何启动目标/guest程序(上面讲了),而且还要熟悉并理解IDB框架导出的API。
悲剧的是,不同框架的API差别还挺大。不幸中的万幸,一般概念对于其中的大多数都适用。正如我之前提到的,我将主要关注Pin。我也会或多或少的尝试在DynamoRIO和Frida中创建相同的功能,所以我们也会熟悉它们的API。请注意,本文的API覆盖范围绝不广泛。如果您想了解更多,我建议您查看每个DBI框架API文档。要阅读这篇文章,您只需了解文中使用的API,而且局限于我选择的用例场景。
任何API设计的意图都是向用户隐藏某些操作的复杂性,同时不削减任何执行任务(包括复杂任务)的能力。我们通常说API越容易使用就越好。
所有这些API都允许我们以某种方式遍历DBI系统即将运行的指令。然后我们可以在指令执行之前对其进行添加,删除,修改或观察。例如,我最初的想法是简单地记录(观察)对内存相关函数(malloc和free)的所有调用。
我们不仅可以添加指令来获取有关程序的分析/跟踪信息,还可以进行更复杂的修改,甚至于用全新的实现完全替换某些指令。例如,考虑用自己实现的malloc实现替换程序运行时的所有malloc调用。
Pin的大多数API例程(routine)都是基于call的。这种API对用户非常友好,至少跟我想象中的DBI系统的使用方式是一致的。稍后你会看到,DynamoRIO有点不一样,但是也差不多。基本上,我们需要注册回调(callback),当某些事件发生时(例如,调用malloc)会通知我们注册的回调。出于性能考虑,Pin是以内联方式安装这些回调的。
大多数DBI框架都支持多种操作系统和架构平台,但是大多数情况下,对于不同的操作系统和平台,API却是相同的,因为不同操作系统之间的差异隐藏在API内部,对用户是透明的。然而,仍然存在某些API是特定于某些操作系统的。你需要意识到这一点。
区分修改(instrumentation)代码和分析(analysis)代码也很重要。修改代码针对特定的代码位置,而分析代码针对在程序执行的某个时刻发生的事件。如维基百科所述,修改例程在未重新编译的代码即将运行时调用,并将分析例程注入。而与分析例程相关联的代码执行时,分析例程才会被调用。换句话说,修改例程决定插入修改代码的位置,分析例程定义修改代码激活时做些什么。
Pin、DynamoRIO和Frida的API,都可以让我们在不同的粒度遍历目标/guest程序。也就是说,在程序的每一条指令执行之前,我们都可以遍历程序的每一条指令,整个基本块,跟踪(多个基本块)或整个目标/guest程序(镜像)的执行。
(第5章结束。文章第2部分正在翻译中,敬请期待)